
A few weeks ago, I was inspired to write an article about the allow_duplicate options and the possible drawbacks of using it.
In this new article, I want to soften my original take and explain when to use allow_duplicate=True and when not to use it with clear examples. Of course, everything you’ll read here is based on my personal experience and might not cover all use cases! 🙂
Let’s dive in!
First, what is allow_duplicate=True?
In Dash, each Output is typically tied to exactly one callback. Attempting to attach an additional callback to the same Output will normally raise an error:
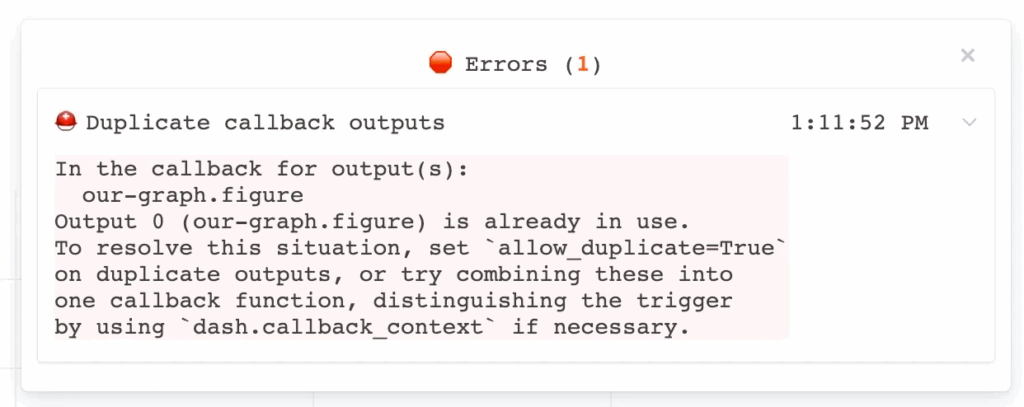
However, since version 2.9 Dash provides an advanced setting—allow_duplicate=True—that lets you break that convention. This flag, placed in the Output declaration, tells Dash that you intend to create another callback targeting the same Output that was already used in a different callback.
Here is an example:
# First callback
@app.callback(
Output('output', 'children', allow_duplicate=True),
Input('input-1', 'value'),
prevent_initial_call=True,
)
def update_output_1(value):
# ... some processing
return value
# Second callback (duplicate output)
@app.callback(
Output('output', 'children'),
Input('input-2', 'value'),
prevent_initial_call=True,
)
def update_output_2(value):
# ... some other processing
return value
Here, both callbacks target the same Output component property. Because the first callback has allow_duplicate=True, the second is allowed to share that same Output. We could just as easily add a third one, or even more.
Note that the allow_duplicate=True is required only for the first callback. But if you change the order callbacks are written in the code, you’ll need to update it. Setting it everywhere makes it less error-prone.
Using this option will also requires setting prevent_initial_call=True to ensures the callbacks don’t get triggered simultaneously (which is what we want to avoid, as you’ll read later).
Pros and cons of allow_duplicate=True
Don’t get me wrong, allow_duplicate=True is useful.
Sometimes we have two distinct user interactions that need to update the same component. As the number of inputs grows, we quickly end up modifying a complex login into a “mega-callback”. It therefore become a nightmare to maintain and little changes can break many behaviors.
Instead, allow_duplicate=True enables splitting the responsibilities into smaller, clearer, more isolated callbacks.
But this goes against the first principle: having only one output per callback, which is generally a good design principle. Not following it has potential drawbacks and trade-offs to consider ⬇️.
Harder to track logic & Maintainability Concerns
Normally in Dash, each property is updated by exactly one callback, so you can always look at that callback to know “what logic is behind this value.” Breaking that rule can lead to confusion: “Wait, which callback is controlling the output now? Or is it both?”
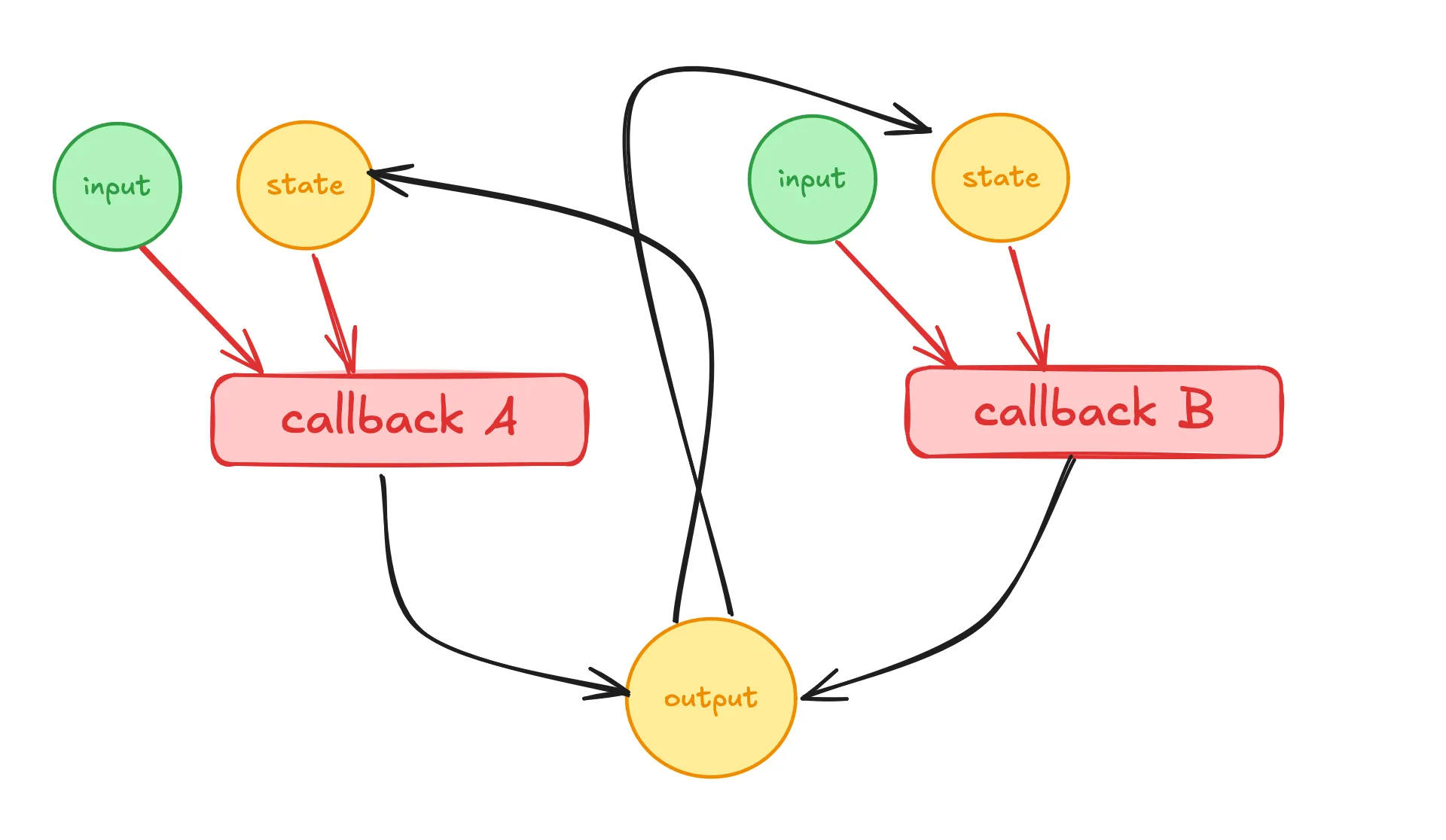
Multiple callbacks returning to the same output can significantly complicate debugging and future maintenance. Other developers (or a future you) might have difficulty quickly discerning how that one visible component is being updated in different contexts.
Potential race conditions
If you have multiple callbacks writing to the same component property at roughly the same time, you may get race conditions—where whichever finishes last overwrites the other. This can cause flickering, inconsistent states, or unexpected behavior if not carefully managed.
This is something that I saw happening and I wrote an article about it in detail here: The dark side of allow_duplicates & making calbacks sequential.
Good use example 1: separate concern
Let’s take an example of fully separated logic.
The following is a true example of a login/register process that I experienced in my app:
@callback(
Output("session_id", "data", allow_duplicate=True),
[
Input("login_button", "n_clicks"),
State("login_email", "value"),
State("login_password", "value"),
],
prevent_initial_call=True,
)
def user_identification(button_n_clicks, username, password):
"""This callback handles the login of a user given a username and password """
# ... handle login
session_id = uuid.uuid4()
return session_id
@callback(
Output("session_id", "data", allow_duplicate=True),
[
Input("register_button", "n_clicks"),
State("register_email", "value"),
State("register_password", "value"),
State("register_lastname", "value"),
State("register_firstname", "value"),
State("register_company", "value"),
State("register_tel", "value"),
],
prevent_initial_call=True,
)
def user_registration(button_n_clicks, email, password, lastname, firstname, company, telephone):
"""This callback handles the registration of a new user"""
# ... handle registration
session_id = uuid.uuid4()
return session_id
Both callbacks handle multiple inputs (email, password, firstname, lastname, etc.) and they return a session_id, that is stored in a session dcc.Store.
This session_id will then trigger another set of callbacks that are related to the loading of an user: displaying its name, loading its preferences, etc.
What’s interesting about this example is that it actually benefited from using allow_duplicate. The two callbacks are different and process a different set of inputs, thus, it makes sense to have two separate callbacks.
This is what it looked like if merged into one large callback:
@callback(
Output("session_id", "data"),
[
Input("login_button", "n_clicks"),
Input("register_button", "n_clicks"),
],
[
State("login_email", "value"),
State("login_password", "value"),
State("register_email", "value"),
State("register_password", "value"),
State("register_lastname", "value"),
State("register_firstname", "value"),
State("register_company", "value"),
State("register_tel", "value"),
],
prevent_initial_call=True,
)
def user_identification_or_registration(login_n_clicks, register_n_clicks, username, password1, email, password2, lastname, firstname, company, telephone):
"""This callback handle the login of a user given a username and password """
if ctx.triggered_id == "login_button":
# ... handle login
session_id = uuid.uuid4()
return session_id
elif ctx.triggered_id == "register_button":
# ... handle registration
session_id = uuid.uuid4()
return session_id
But large callbacks also have their own drawbacks: harder to maintain, multiple inputs to handle, etc… Plus, we would be sending unnecessary information with every callback trigger—making it less efficient
In this case, allow_duplicate proves really helpful in reducing the complexity and making a more readable and maintainable code.
Prior the introduction of allow_duplicate, I actually handled this with two dcc.Store : session_id_login and session_id_register, which were both triggering a callback updating a single output: session_id. They were used as temporary storage —but that was less efficient and required one round trip to the server as well as one unecessary callback execution.
Good use example 2: partial update
The previous example illustrated how allow_duplicate can help separate callbacks when logic is different. It’s more about callback designing, but there are solutions to do it without allow_duplicate.
The following example could not be possible without the help of allow_duplicate .
Imagine you have a figure. And you want to update only the title of a figure without redrawing the whole figure. The code would look like:
@callback(
Output('graph', 'figure', allow_duplicate=True),
Input('dropdown', 'value'),
prevent_initial_call=True,
)
def update_graph(value):
# Download very large data from a server
df = pd.read_csv('https://.../data.csv')
fig = px.line(df, x='date', y='value', color='category')
return fig
@callback(
Output('graph', 'figure'),
Input('title_input', 'value'),
prevent_initial_call=True,
)
def update_title(title):
# Just modify the title with Patch()
fig = Patch()
fig['layout']['title'] = title
return fig
In update_graph, we load a large dataset and return a figure. In the other callback update_title, we only update the title of the figure and return it, using Patch().
What’s wonderful here is that the use of allow_duplicate and Patch() conjointly helped updating the figure without the need to reload the whole data and create the entire figure again.
It’s a more efficient solution, that would translate in a more responsive application and a better user experience.
Lean more about partial updates here: https://dash.plotly.com/partial-properties
In this case, allow_duplicate enabled something that wasn’t possible before.
Bad use example 1: harder to track
The following is a fictitious bad example, and/or bad callback design, where two callbacks update the same container:
@callback(
Output("results_container", "children", allow_duplicate=True),
Input("search_button", "n_clicks"),
prevent_initial_call=True,
)
def search_results(n_clicks):
"""This callback searches for results when the search button is clicked"""
if n_clicks is None:
raise PreventUpdate
# some processing
return [
html.Div("Search results from button click"),
html.Div([html.Span(f"Result {i}") for i in range(5)])
]
@callback(
Output("results_container", "children", allow_duplicate=True),
Input("filter_dropdown", "value"),
prevent_initial_call=True,
)
def filter_results(filter_value):
"""This callback filters results when dropdown value changes"""
if filter_value is None:
raise PreventUpdate
# some processing
return [
html.Div(f"Filtered results for: {filter_value}"),
html.Div([html.Span(f"Filtered item {i}") for i in range(3)])
]
Both search_results and filter_results can be triggered . If both are triggered at the same time, we will have either one result or the other (the last callback being executed), which is misleading.
The issue here is that we’re using one single container, result_container, to display two different solution. And allow_duplicate=True made it possible.
To be clear, the above code will work. It’s just that in my opinion, this is not a good use of allow_duplicates for the sake of maintainability and callback logic.
Instead, it would have been better to just have two separate containers (e.g. a new search_result_container and filter_result_container) or to merge the logic into one callback. ✅
Bad example 2: race condition
This example will illustrate the race condition problem.
Imagine you need to store the number of clicks on two buttons in a list. The first button increments the first count, and the second button updates the second count:
# Our dcc store is like this:
results_store = [0, 0]
@callback(
Output("results_store", "data", allow_duplicate=True),
Input("button1", "n_clicks"),
State("results_store", "data"),
prevent_initial_call=True,
)
def update_store_from_button1(n_clicks, current_data):
""" Store the number of clicks on button1"""
# Sleep randomly to simulate network latency
time.sleep(random.uniform(0.5, 2))
# Update button 1 count
current_data[0] = n_clicks
return current_data
@callback(
Output("results_store", "data", allow_duplicate=True),
Input("button2", "n_clicks"),
State("results_store", "data"),
prevent_initial_call=True,
)
def update_store_from_button2(n_clicks, current_data):
""" Store the number of clicks on button2"""
# Sleep randomly to simulate network latency
time.sleep(random.uniform(0.5, 2))
# Update button 2 count
current_data[1] = n_clicks
return current_data
Each callback is triggered by its button, uses the state of current_data and returns the updated value.
Let’s give an example:
- click on button1 → … add one to the number of clicks (current data state is
[0, 0]) … → the callback returns[1, 0] - then click on button2 → … add one to the number of clicks (current data state is
[1, 0]) … → the callback returns[1, 1]
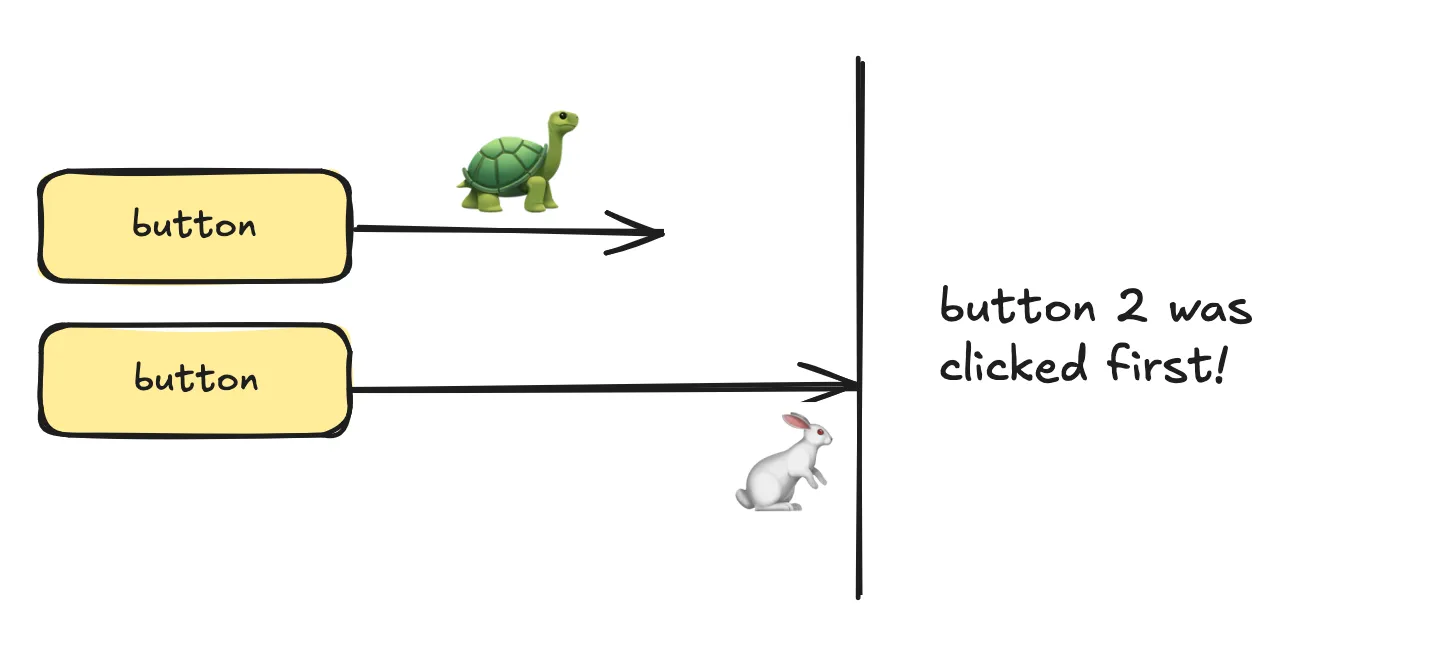
This is all good because we click and wait for the callback to be fully executed. Now, what if we click to both buttons at the same time ?
- click on button1 → … add one to the number of clicks (current data state is
[1, 1]) … → the callback returns[2, 1] - click on button2 → … add one to the number of clicks (current data state is
[1, 1]) … → the callback returns[1, 2]
Depending on which callback finishes first, we’ll get different results: [2, 1] or [1, 2].
You can try a live demo below (or click here):
In this example, I chose to simulate network latency with time.sleep() so that the problem is emphasized. When testing locally, you might not notice the problem—but it can become obvious once deployed to production.
In this case, a better solution would have been to
- use
Patch()to be sure we do not rely on states - use different
dcc.Storeto store the two information.
I hope this example helped to understand race conditions. 😉 Again, this other article also illustrates this problem.
Conclusion
I hope this article helped you to understand what are the good and bad practices with this powerful option, allow_duplicate.
If you’re unsure when to use it, here are a few rules I’ve come up with:
- If you have two separate callback logic that depend on which inputs are triggering the callback (i.e. with
ctx.triggered), and have a different set of inputs, then creating two callbacks withallow_duplicatemay be a good solution ✅ - If the callbacks (or more) are never supposed to be triggered at the same time, you are also safe to use
allow_duplicatebut consider using different outputs if possible ✅ - If you need to update partially a component (e.g. a figure) using Patch, then
allow_duplicateis your only option. ✅
I you have questions or want to join the discussion, I created at topic here: plotly forum.
— Happy coding! ⭐
